全自動麻雀卓を買った。
こんにちは、たまごはん です。
ついに待望の全自動麻雀卓 AMOS JP-EX COLOR を手に入れたぞ~!
届いてすぐに組み立てて動かしましたが、『感動』の二文字に尽きますね…。
今回、もともと和室に置く予定だったので座卓兼用タイプを買いましたが、長時間遊びすぎて腰を痛めないか心配です。もしダメだと思ったら立脚で遊ぶようにします。
あ~早くみんなと遊びたいっ!
P.S. 三麻用のゴッドハンドってみんな買ってるんでしょうか。欲しいけど 2 万円以上するってのがネックですね…。ラズパイとかで頑張れば 2 万円以下で似たようなものをつくれる気がしなくもない。
ボードゲーム『DOBBLE』の数学
こんにちは、たまごはん です。
『DOBBLE(ドブル)』というボードゲームをご存知でしょうか。
ドブルは、それぞれに50種類以上のマークの内から8つが描かれた55枚のカードで遊ぶゲームです。全てのカードは他のカードとたった1つだけ共通するマークが描かれており、それを探すことがゲームの目的です。
ゲームの説明にもあるように、55 枚のそれぞれのカードには 8 個の異なるマークが描かれていて、どの 2 枚についても共通するマークが たった一つだけ となるようになっています。
この説明を読んだとき、非常に面白い性質だなぁと思いました。しかして、マークの種類やカードの枚数、カードに描かれるマークの数などの数学的な関係性について調べたくなりました。
色々と調べたら案の定、すでに数学的性質について研究している方々がおりました。
結果をまとめると、ゲーム性を保つような条件下でカードに描かれるマークが 個のとき、マークの種類とカード枚数はいずれも最大で
になるようです。また、各マークは
枚のカードに描かれています。
先人たちは射影平面上で議論していたりして「そこまで発展するのか…」と驚くばかりです。
ちなみに、3 つ目のリンク先には、 枚のカードを出力してくれる JavaScript のコードが載っていました。以下は、それを Python で書き換えたものになります。
def f1(n, j, k): return n + n * j + k + 1 def f2(n, i, j, k): return n + 1 + n * k + (i * k + j) % n number_of_symbols = 4 # カードに描くマークの個数 n = number_of_symbols - 1 card = list(range(number_of_symbols)) cards = [card] # マーク 0 で共通するカード for j in range(n): card = [0] + [ f1(n, j, k) for k in range(n) ] cards.append(card) # マーク i + 1 で共通するカード for i in range(n): for j in range(n): card = [i + 1] + [ f2(n, i, j, k) for k in range(n) ] cards.append(card) for card in cards: print(card)
それでは。
麻雀の役を覚えたい
こんにちは、たまごはん です。
麻雀やっていると「この役って何翻だっけ?」「喰い下がりあったっけ?」みたいなことをいつもやっているので、ちゃんと覚えなきゃいけないなぁと感じています。
ただ、ネットで調べて出てくるのってそれぞれの役が個別に解説されていたり、あるいは、鳴き OK や喰い下がりなどの記載なしに翻数ごとにまとめていたりで、個人的には使いづらいものばかりでした。
そんなわけで自分用に作りました。それぞれの役が何翻で、鳴き OK なのか、喰い下がり有なのかがぱっと見で分かるようなものが欲しかったので、このような表になっています。
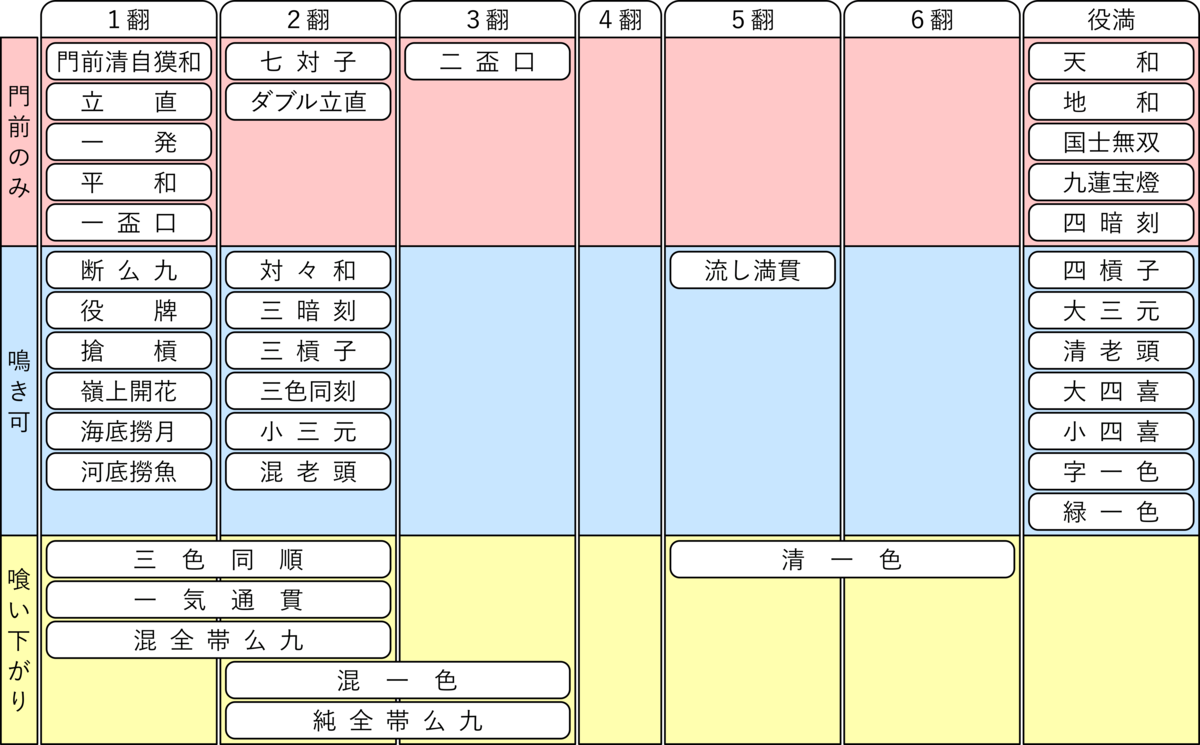

『門前のみ』は「一度でも鳴いてしまうと成立しないので要注意」という意味を込めて赤色にしています。同じように、『喰い下がり』も「鳴いても成立するが 1 翻下がるので注意」という意味で黄色にしています。これら以外は鳴きを気にしなくていいので青色にしています。
念のため、上記のカラーリングに合わせた役ごとの成立条件も作成しました。個人的に留意すべき点があったものに関しては赤字で補足しています。
一応、いくつかのサイトと照らし合わせながら作成したので致命的なミスは無いと思います。ただ、成立条件についてはざっくりとした説明しかしていないので、厳密な条件はちゃんとしたサイトなどを参考にしてください。
なお、ローカル役の流し満貫は、自分たちはいつも有りでやっているので載っけています。
それでは。
参考
久々の麻雀、難しい…。
こんにちは、たまごはん です。
先日、数ヶ月ぶりに麻雀をしました。今年始めたばかりの数ヶ月間はほぼ毎日していたのに、気が付けば全くしてませんでした。たぶん夏季休暇あたりからだと思います。
そんなこんなで久々に麻雀をしたんですが、(あの頃の自分に比べて)めちゃくちゃ弱くなってました。ハマってた頃はスジやカベなども意識してプレイできていたのに、今回は自分の手牌を育てていくのに精一杯で何度も放銃しました…。
それでもやっぱり面白いことには変わりなく、再び麻雀にハマりつつあります。それに、あの頃と違って家にほぼ使っていない部屋があるので、全自動麻雀卓を買っても良いかなぁと思い悩む今日この頃です。
とりあえず、引き際を見極められるように頑張ります。それでは。
AT 限定解除について その後 2
こんにちは、たまごはん です。
AT 限定解除した友人の話の続きです。先日、3 回目の MT 練習をしてきました。
最初のときはクラッチの踏み込みが甘いわ、何速に入れてるか覚えてないわで MT に向いていないと思っていましたが、徐々に慣れてきたのかその辺の問題はなくなってきました。それに市街地もほぼ問題なく走れるようになってきました。
次に解決すべき課題としては
- ギアチェンジの動作が遅い
- 適切なギアの選択ができていない
の 2 つかなと思っています。
一般に、ギアチェンジ時には「クラッチを踏む」「ギアを変える」「半クラを介してクラッチを離す」という動作が行われています。MT に慣れてる人はこれらをほぼ同時、つまり、クラッチを踏むと同時にギアを素早く変え、すぐに半クラしてクラッチを離していると思います。
しかし、友人は動作の一つ一つを順番に行ううえに動作間に一定の間があるので、結果としてギアチェンジに 1 秒以上かかっているのが現状です。もちろん、まだまだ MT 初心者なので仕方がないと言えばそれまでなんですが、本人の目標が「ブリッピング・シフトダウンができるようになる」らしいので、いずれ直していかないといけない部分です。
それに、ギアチェンジに時間をかけ過ぎてしまうとエンジンの回転数が落ちすぎてしまって、シフトアップ時にも強い変速ショックが起きてしまいます。半クラでショックを抑えることもできますが、半クラの時間が長くなってしまってクラッチに良くないので、やっぱり直していきたい部分ですね。
次回以降は、同時とは言わずとも素早くギアチェンジすることを意識して走ってもらいたいと思っています。
適切なギアの選択ができていないというのは、シフトアップ/シフトダウンするタイミングや状況の判断がまだまだ未熟ということです。
例えば、4 速で十分なところを 3 速のまま高回転数で走り続けたり、前方で徐行している車列に 5 速で追いついたあとに 3 速とかにシフトダウンせずに加速しようとする、などです。特に、シフトダウンについては「エンジンブレーキを効かせたいときに行う」という認識が強く、徐行になってからの加速時にシフトダウンするという発想がまだ身に付いていないようでした。
また、曲がろうと思っていた交差点が赤信号になったときに、停車するにもかかわらず停車直前に 2 速にシフトダウンすることも何度かありました。恐らく「2 速に入れて曲がる」という動作を行なってしまっているせいなので、数秒先の動作を予測したうえでの運転を意識してもらいたいと思っています。
次回は自分とその友人以外の友人も乗せて運転する予定なので楽しみです。それでは。
iTunes ライブラリを外部ストレージに移動した。
こんにちは、たまごはん です。
ここ数日、急に気温が下がってきましたね。一昨日まではリビングで冷房をかけていましたが廊下のほうが涼しいことに気付き、急遽、窓を開けて扇風機に切り替えました。
さて、引っ越してから長らく放置していたんですが、iTunes ライブラリを移行させました。もともと実家の PC の iTunes で管理していたので、引っ越しに伴って自分のノート PC の iTunes で管理し直す必要がありました。
ただ、ノート PC のストレージが 256 GB しかなく、ここにすべての楽曲データを放り込んでしまうと他のデータとの兼ね合いで容量不足になる可能性が高いので、外部ストレージで管理することにしました。
フォルダやメタデータなどを整理する。
本来これは別にしなくていい作業なんですが、自分の性格的にどうしても我慢できなかったので Python などを用いて行いました。実施した内容としては、
- 楽曲ファイル名の先頭にトラック番号を付ける。
- 複数ディスクに分かれているアルバムの楽曲は同じフォルダに突っ込み、ファイル名のトラック番号の先頭にディスク番号を付ける。
- キャラソンなどはその作品フォルダを作成し、その下にアーティスト別に配置する。
- アーティスト名やアルバム名を読み方も含めて統一する。
などです。これだけで優に数週間も経ってしまいました…。でも自分なりに妥協できるレベルまで整理できたので、ようやく iTunes に取り込みます。
iTunes に取り込む。
Web で色々と調べた結果、Shift を押しながら iTunes をダブルクリックするといいみたいでした。ポップアップで「ライブラリを選択する」と「新規作成する」が出てくるので、新規作成のほうをクリックして外部ストレージを選択して決定すると、外部ストレージのほうに自動的に基本的なファイルやフォルダが作成されるようです。
自動で作成されたフォルダの一つに「iTunes Media」があるので、その下に先ほど整理した楽曲データ(フォルダごと)を放り込みました。
その後、iTunes の左上にある「ファイル」から「フォルダをライブラリに追加」をクリックして、先ほど作成した「iTunes Media」を選択して決定すると、楽曲データの取り込みが始まります。曲数にもよりますが、自分の場合は 30 分くらいで完了した気がします。
少々問題が…
無事めでたしめでたし、となるかと思いきや少し問題が発生してました…。
自分の Apple アカウントで Apple store から購入した楽曲 以外 には問題なかったんですが、購入した曲のアーティスト名やアルバム名などが Apple store で購入した初期状態のままになってました。おかげさまでアーティスト名がローマ字になってたりするので、同じアーティストなのに異なるアーティストとして管理されてしまうといった状況でした。
一応、楽曲を右クリックして「曲の情報を見る」で確認すると整理した後の状態になっていて、この段階で iTunes もそれを認識してその曲 のみ 情報が更新される感じです。これが数曲だけなら良かったんですが、数百曲は購入してるので全部やるのは面倒過ぎます。
Apple store 上のメタデータではなく、ファイルのメタデータを基準にファイルを読み込んでくれるような方法を探しましたが、それらしい解決策は見つからず…。一応、「iTunes Library.xml」で曲ごとのメタデータが管理されているらしいので、これをテキストエディタで直接または Python などでいじってみようと思います。
いやぁ~どうなることやら。それでは。
駐車場に落とし穴
こんにちは、たまごはん です。
先日、車がシャコタンになってました——否、右前輪のあった部分が陥没してました。…衝撃です。

車に乗り込もうとしたとき、なんだか車高が異様に低いとは感じていたんですが、まさか地面が陥没していたせいだとは思いませんでした。というか、自分が経験するとは考えたこともなかったです。
車を安全な場所に移動させてから確認したところ、20 cm × 40 cm くらいの穴が開いてました。そこにタイヤが 10 cm ほど地面にめり込んだ状態だったみたいです。
恐らくずっと前からコンクリートの下の土砂は陥没していて、今月に自分が引っ越してきたことで車重によって徐々にコンクリートが凹んでいき、ついには耐えきれなくなって穴が開いたんだと思います。穴の奥は少し広がっていたので穴の周囲は要警戒ですね。
一応、穴のすぐ隣に下水の集積場?があってその領域を市に貸している状態らしく、市のほうでどうにか対処できないか相談しているところです。まぁ隣にあるだけでそれが原因かどうかは不明なので、自費で直すことになりそうですが…。
たぶんあと数時間も経っていたら右前輪が完全に地面に飲み込まれて、車の底が地面に擦ってしまってたんじゃないかと思うと九死に一生を得た気持ちです。
果たしてどれくらい費用かかるのかなぁ~。それでは。
AT 限定解除について その後
こんにちは、たまごはん です。
先日、AT 限定解除した知り合いの MT 練習をしてきました。
2 ~ 3 週間前に AT 限定解除してから一度も MT 車を運転していないとのことだったので、まずは近所にあるお寺の駐車場で発進や停止などの基本的な操作を復習しました。お寺からは少し離れたところにある無料の駐車場でそれなりに広く、しかも車止めもないため、練習にはもってこいの場所でした。
その後、近くのドライブウェイに行き、もう少し実践的な練習をしました。もちろん車通りはほぼ 0 ですし、信号機も交差点も無いので実際の街中とは全然違いますが、教習所内では出せない速度、ギア(4 速以上)の体験や坂道発進、シフトダウンなどを練習しました。
途中で昼休憩を取ったあと、実際に街中を走行してもらいました。一応、道幅が広く、車通りが多くはない場所を選びました。街中に出ると周囲に車や人がいるせいか緊張したり焦ったりして、余計にシフト操作やペダル操作が疎かになってしまいエンストすることが多かったです。まぁ初心者あるあるですね。
練習していて特に気になったのが、
- クラッチの踏み込みが甘い
- 自分がいま何速で走っているのかを把握していない
の 2 つです。
1 つ目については、クラッチの踏み込みが甘いせいでシフトが奥まで入っていない(=ニュートラル)にもかかわらず、本人は入ったと思っているのでアクセルを踏んで空ぶかししてしまい、加速しないのとエンジン音に焦ってさらにアクセルを踏み込んでしまうということが何度もありました。また、停車や駐車の際にも気が付けば半クラ状態になっていて、静かにエンストするということもありました。
2 つ目については、「1 速から 2 速」や「2 速から 3 速」をすべて「ギアチェンジした」で理解しているんじゃないかと思いました。そのため、ギアチェンジしたことは覚えていても自分が何速なのかまでは覚えていないんだろうと思います。
もちろん、ときどき忘れてしまう分にはいいんですが、知り合いは指摘されても練習の最後の最後まで把握できておらず、頻繁にシフトを目視していました。これは結構危険だと思うので根気よく指摘して意識してもらえるようにします。
朝から晩まで練習を見た感想としてはまだまだ教習レベルだと思いました。それに教習であれば月に数回は練習できますが、次に練習するのは 1 ヶ月以上も先になりそうなので、身に付くものも身に付かないんじゃないかと思ってます。中古で良いからぜひ MT 車を買って、週 1 回でもいいから練習してほしいですね。
それでは。
AT 限定解除について
こんにちは、たまごはん です。
野球の大谷選手があまりにも漫画の主人公過ぎて驚かされる毎日です。WBC の最終局面でのトラウトとの対戦とかサヨナラ満塁 HR で 40-40 を決めるとか、創作の世界ならもはややり過ぎなくらいです。
このまま 50-50 も達成してしまうんじゃないかとニュースを見るたびドキドキしてます。
さて、最近になって知り合いが AT 限定解除しました。普段から AT 車を運転している方なので今さら感は拭えないんですが、身近に MT 車を運転できる人が増えるのは嬉しいです。
解除するに至った経緯とかいろいろ聞いていて驚いたんですが、AT 限定解除のときって教習が数回しかないうえに路上にも出ないんですね。
普通に MT 免許を取るよりかは少ない回数で解除できるとは思っていましたが、まさかの 3、4 回程度とは思ってもみませんでした。そんな回数じゃ MT 車を運転できたとしても一過性のもので、身近に MT 車がないとすぐに忘れてしまうんじゃないかと思います。
まぁ MT 車が身近にある環境だから AT 限定解除する(したくなる)のかなとも思うので、回数はそこまで気にしなくていいんですかね…。
ただ路上教習は一回くらい実施したほうがいい気がするんですよね。交通状況を把握しながらギアチェンジしたり、40~50 km/h で走ってみたりとかは教習所内では体験できないので、1 回か 2 回くらいは経験させたほうが教習生も安心できそうですけどね。
でも路上に出るとなると回数をこなしてからじゃないとエンストしまくったり焦ったりして危険だし、やはり教習の回数を増やす必要があるのか…。
う~ん、悩ましい。
そんなわけで今度、その知り合いに MT 車の運転を教えることになりました。これまで教えてもらうことはあっても教えたことはないので結構緊張してます。
ひとまずの目標としては『発進、加速、減速、停止に伴うシフト、ペダル操作を覚える』にしました。
まだ実際の運転を見てはいませんが、これまで長いこと AT 車を運転してきたことや教習の回数が少ないことを踏まえると、シフト操作やクラッチ操作を忘れてしまいがちになるような気がします。なので、その辺りを重点的に鍛えようかなと思います。
ある程度慣れてきたら実際に街中を走ってみて、周りの交通状況を把握しながらの運転に慣れてもらおうかなと考えてます。ただ、シフトとかクラッチを意識し過ぎると今度は他のところに注意が向かなくなって危険なので、そこの判断は難しいところですね。
……とりあえず事故しないように頑張って教えます。
それでは。
Python: pixiv からイラストをダウンロードするだけ
こんにちは、たまごはん です。
漫画やイラストが好きなので、よく pixiv で色々な作品を鑑賞しています。そして、気に入ったものがあれば自分の PC に保存して、作者さんごとにコレクションしています。
その際、これまでは一つ一つのイラストを「右クリック → 保存」で保存していたんですが、作品によっては複数枚のイラストが含まれていたりして非常に面倒なこともありました。そこで、Python で半自動的に保存させるようにしました。
作品のダウンロード
Python 向けの pixiv API としては PixivPy が知られています。いろいろな記事で紹介や解説されているので、非公式 API とはいえ、そこまで怪しいものではないと思っています。
ただ、ログインのためにアクセストークンを取得する必要があったり、機能の豊富さゆえにイラストをダウンロードするだけでコードが複雑になってしまう気がしたので、一から自分で書いたほうが楽だなと思いました。…それに自分で作れば自由にカスタマイズできるので。
さて、pixiv に投稿された作品には、固有の番号1(以下、作品 ID)が割り振られています。これを利用して、以下の 2 ステップでイラストをダウンロードします。
- 作品 ID からイラストの URL を取得する。
- 取得した URL からイラストをダウンロードする。
ステップ 1.イラスト URL の取得
一つ一つの作品には、1 枚以上のイラストが含まれています。以下の get_illust_uls 関数は作品 ID artwork_id を受け取って、その作品に含まれる全イラストの URL を返します。なお、うごイラは対象外です2。
import json import requests from bs4 import BeautifulSoup from datetime import datetime # URL のプレフィックス PIXIV_URL = "https://www.pixiv.net/" ARTWORK_URL = "https://www.pixiv.net/artworks/" PXIMG_URL = "https://i.pximg.net/img-original/img/" def get_illust_urls(artwork_id): # 作品 URL artwork_id = str(artwork_id) artwork_url = ARTWORK_URL + artwork_id # イラストデータの取得 html = requests.get(artwork_url, headers = {"Referer": PIXIV_URL}, stream = True) soup = BeautifulSoup(html.text, "html.parser") meta_data = soup.find(id="meta-preload-data") contents = json.loads(meta_data.get("content")) illust_data = contents["illust"][artwork_id]["userIllusts"][artwork_id] # イラストの枚数・更新日時の取得 number_of_pages = illust_data["pageCount"] update_date = datetime.fromisoformat(illust_data["updateDate"]) update_date = update_date.strftime("%Y/%m/%d/%H/%M/%S") # うごイラ(illustType: 2)の除外 if illust_data["illustType"] == 2: return [] # イラスト URL の作成 url_prefix = PXIMG_URL + f"{update_date}/{artwork_id}" illust_urls = [ url_prefix + f"_p{i}." for i in range(number_of_pages) ] return illust_urls
最後の「イラスト URL の作成」から分かるように、イラスト URL は以下の情報があれば推測できます(2024 年 8 月現在)。
- 作品 ID
artwork_id - 更新日時
update_date - イラストの枚数
number_of_pages
ただし、この段階ではイラストのフォーマットが JPEG なのか PNG なのかは分からないため、拡張子を付けていません。正しい拡張子を知るためには手動または Selenium 経由で確認するのが定石かと思いますが、ログインしなくちゃいけなかったりと面倒なので別のアプローチを考えます。
ステップ 2.イラストのダウンロード
ステップ 1 で取得したイラスト URL を通じて、それぞれのイラストをダウンロードしていきます。
いくつかのイラストを確認したところ、拡張子としては jpg / jpeg / png の 3 つがありました。特に、ほとんどのイラストは jpg か png で、ごく稀に jpeg があるといった様子でした。そこで、拡張子を jpg → png → jpeg の順で変えながら、正常にダウンロードできた段階で次のイラストに移るようなアプローチを取ります。
以下の download_illusts 関数はイラスト URL のリスト illust_urls を受け取って、各イラストのバイナリデータと正確なイラスト URL を返します。
import requests import time def download_illusts(illust_urls): # ダウンロード用セッション session = requests.Session() session.stream = True session.headers = { "Content-Type": "document", "Referer": PIXIV_URL } # 拡張子ごとにダウンロードを試す extensions = ["jpg", "png", "jpeg"] for illust_url in illust_urls: for extension in extensions: response = session.get(illust_url + extension) time.sleep(0.3) if response.status_code == 200: break else: # どの拡張子でもダウンロードできない場合はエラー response.raise_for_status() yield response.content, illust_url + extension
実は、2024 年 8 月中旬までは
response = requests.get(illust_url + extension,
headers = {"Referer": "https://www.pixiv.net/"}
stream = True)
で問題なかったんですが、突然 403 エラーを吐くようになってしまいました。
いろいろと調べた結果、どうやらイラスト URL へアクセスしたときに favicon.ico が最初に読み込まれているみたいなんですが、そこで 403 エラーが起き、その後にイラストが読み込まれて表示されている、といった様子でした。また、favicon.ico の Centent-Type が text/html であり、エラーの出たあとに response.headers を確認すると Content-Type が text/html になっていました。
従って、上記のコードを実行した場合、favicon.ico で起きた 403 エラーを先に拾って返してくるので、その後のイラストが返って来なかったんだと思います3。ただ、以前までの状況が不明なため断定はできません。
その後、試行錯誤して上記のコードに行き着きました。
ステップ 1 とステップ 2 の統合
ステップ 1 とステップ 2 を統合して、与えられた作品 ID のイラストを指定したフォルダに保存できるようにします。
import re def save_illusts(artwork_id, save_dir="."): # イラスト URL の取得 illust_urls = get_illust_urls(artwork_id) for illust, url in download_illusts(illust_urls): # ファイル名 filename = re.search(r"(?<=/)[^/]+$", url).group() # 保存 illust_file = save_dir + "/" + filename with open(illust_file, "wb") as f: f.write(illust)
使い方
例えば、作品 ID 123456 のイラストをディレクトリ ./output に保存したい場合、以下のようにします。
artwork _id = 123456 save_dir = "./output" save_illusts(artwork_id, save_dir)
あとは自由に改良したりしてください。それでは!
- https://www.pixiv.net/artworks/*** の *** 部分です。↩
- 個人的に不要だったので。↩
- HTTP や web などの知識に乏しいため、間違えている可能性も十分あります。その際はご指摘頂けると助かります。↩